让建站和SEO变得简单
让不懂建站的用户快速建站,让会建站的提高建站效率!

复旦大学副老师郑骁庆谈DeepSeek:AI行业不独一“规模规章”,开源将加快模子更新,芯片需求可能不降反增
每经记者 宋欣悦 每经剪辑 高涵
近日,中国AI初创公司深度求索(DeepSeek)在全球掀翻波浪,硅谷巨头惊骇,华尔街错愕。
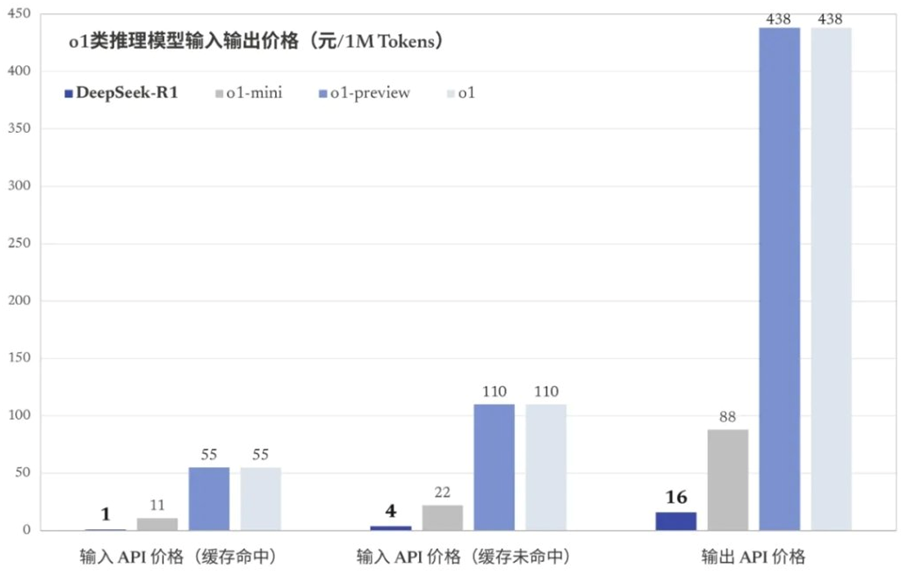
短短一个月内,DeepSeek-V3和DeepSeek-R1两款大模子接踵推出,其老本与动辄数亿甚而上百亿好意思元的国际大模子名堂比拟号称便宜,而性能与国际顶尖模子额外。
动作“AI界的拼多多”,DeepSeek还动摇了英伟达的“算力信仰”,旗下模子DeepSeek-V3仅使用2048块英伟达H800 GPU,在短短两个月内磨练完成。除了性价比超高,DeepSeek得到如斯高的热心度,还有另一个原因——开源。DeepSeek透彻松懈了以往大型言语模子被少数公司控制的场面。
被誉为“深度学习三巨头”之一的杨立昆(Yann LeCun)在酬酢平台X上默示,这不是中国追逐好意思国的问题,而是开源追逐闭源的问题。OpenAI首席推行官萨姆·奥尔特曼(Sam Altman)则疏远地表态称,OpenAI在开源AI软件方面“一直站在历史的不实一边”。
DeepSeek具有哪些创新之处?DeepSeek的开源计策对行业有何影响?算力与硬件的主导地位是否会迟缓被平缓?
针对上述疑问,《逐日经济新闻》记者(以下简称NBD)专访了复旦大学谈判机学院副老师、博士生导师郑骁庆。他认为,DeepSeek在工程优化方面获取了显赫抑止,越过是在缩小磨练和推理老本方面。“在业界存在着两个规章,一个是规模规章(Scaling Law),另外一个规章是指,跟着技艺的约束发展,在既有技艺基础上捏续革命,大概大幅缩小老本。”
关于DeepSeek弃取的开源计策,郑骁庆指出,“开源模子大概招引全宇宙顶尖东谈主才进行优化,对模子的更新和迭代有加快作用。”此外,开源模子的透明性有助于摒除使用安全的费心,促进全球范围内东谈主工智能技艺的平正哄骗。
尽管DeepSeek的模子缩小了算力需求,但郑骁庆强调,AI模子仍需要一定的硬件基础来接济大规模磨练和推理。此外,大规模数据中心和预磨练仍是AI发展的进犯构成部分,但异日可能会更瞩目高质料数据的微和谐强化学习。

郑骁庆 图片起原:受访者供图
NBD:微软CEO萨提亚·纳德拉在微软2024年第四季度财报电话会上提到,DeepSeek“有一些信得过的创新”。在您看来,DeepSeek有哪些创新点呢?
郑骁庆:在真切研读DeepSeek的技艺呈文后,咱们发现,DeepSeek在缩小模子磨练和推理老本方面遴荐的设施,大多基于业界已有的技艺探索。比如,键值缓存(Key-Value cache)料理,对缓存数据进行压缩。另一个是搀和行家模子(MoE,Mixture of Experts),现实上是指,在推理的时候,只需使用模子的某一个特定的模块,而不需要系数模子的集聚结构和参数都参与这个推理过程。
此外,Deepseek还遴荐了FP8搀和精度磨练的技艺妙技。这些其实之前都有所探索,而DeepSeek的创新之处就在于,很好地将这些大概缩小技艺和推理老本的技艺整合起来。
NBD:您认为DeepSeek现阶段的技艺水平上是否依然接近或者达到了全球动身点水平呢?
郑骁庆:DeepSeek咫尺在现存技艺基础上,包括集聚结构磨练算法方面,竣事了一种阶段性的革命,并非是一种现实上的颠覆性创新,这少许是比较明确的。其革命主如果针对特定任务,举例,DeepSeek在数学、代码处理以及推理任务等方面,提议了一种在性能与老本上相对均衡的处置决策。然则,它在洞开领域(open domain)上的阐扬,上风并不是十分显然。
在业界存在着两个规章,一个是规模规章(Scaling Law),即模子的参数规模越大、磨练数据越多,模子就会更好。另外一个规章是指,跟着技艺的约束发展,在既有技艺基础上捏续革命,大概大幅缩小老本。
比如说,以GPT-3为例,早期它的老本就很高。但跟着盘问的真切,盘问东谈主员迟缓了了哪些东西是使命的,哪些东西是不使命的。盘问东谈主员基于过往的得手训导,盘问主义会迟缓澄莹,老本现实上也会随之缩小。
DeepSeek的得手,我更认为可能是工程优化上的得手。虽然也相当欢欣看到中国的科技企业在大模子的期间,在性能与老本的均衡方面获取了显赫进展,约束推动大模子的使用和磨练老本下落。稳妥刚才我提到的第二个规章的情况之下,走到宇宙前线。
NBD:DeepSeek旗下模子的最大亮点之一是在磨练和推理过程中显赫缩小了算力需求。您认为这种低老本大效用的技艺创新,弥远来看,会对英伟达等芯片公司产生什么影响呢?
郑骁庆:我个东谈主认为,它并不会对芯片采购量或出货量产生太大的影响。
动身点,像DeepSeek或者访佛的公司,在寻找有用的整合处置决策时,需要进行多半的前期盘问与消融实验。所谓的消融实验,即指通过一系列测试来细目哪个决策是有用的以及哪些决策的整合是有用的。而这些测试就相当依赖于芯片,因为芯片越多,迭代次数就越多,就越容易知谈哪个东西使命或者哪个东西不使命。
比如说,DeepSeek的磨练预算不到600万好意思元。它的技艺呈文中提到,不到600万好意思元的资金,是按照GPU的小时数(每小时两好意思元)来估算的。也就是说,他们基于之前的好多盘问,把整条磨练过程都依然搞了了的情况之下(哪些是使命,哪些不使命的),再行走一遍。它的GPU的运算速率是几许,运算小时数是几许,然后再乘以每小时两好意思元得到的这个抑止。呈文中也提到了,600万好意思元其实莫得包含先期盘问老本,比如,在结构上的探索、在算法上的探索、在数据上采采集上的探索的老本,也莫得涵盖消融实验的支拨以及成就的折旧费。是以,我个东谈主判断,对英伟达其实影响不是那么大。
另外,DeepSeek的盘问标明,好多中小企业都能用得起这么的大模子。尽管磨练老本的下落可能会暂时减少对GPU的需求,但大模子变得愈加经济,会使蓝本因为模子老本太高而不盘算使用大模子的企业,加入到使用模子的行列,反而会增多关于芯片的需求。
NBD:跟着DeepSeek-V3、R1等低老本大模子的问世,传统的大规模数据中心和高参加的大模子磨练是否仍然值得不绝推动呢?
郑骁庆:我认为仍然值得。因为动身点DeepSeek模子是言语模子,还莫得膨胀到多模态,甚而于咱们以后要盘问宇宙模子。那么一朝引入多模态之后,对算力的要乞降基础圭臬条目就会成指数的增长。因为东谈主工智能不行能只是局限于言语体本人,言语只是灵敏的一种阐扬,而在这方面的探索仍然需要这么的一个基础圭臬。
刚才也提到DeepSeek其实是在好多先期盘问的基础之上,找到了一条性能和老本均衡的一个处置决策。先期盘问包括多样种种的尝试,怎么去加快它呢?这个如故需要雄壮的硬件接济。不然,每迭代一次,就可能需要长达一年多的时候,这显然是无法赶上咫尺AI武备竞赛的。而如果有几万张卡,迭代可能几天就完成了。
另外就是哄骗方面。即即是模子的推理老本再低,当需要接济数千、数万甚而更大规模的并发使用时,仍然需要一个配备多半显卡的雄壮基础架构来确保庄重启动。
我认为大规模预磨练这一波潮水可能会弱化,可能不会成为下一步寰球争夺的主战场。之前这个领域曾是竞争横蛮的战场,但咫尺看来,老本和产出之间的比例正迟缓趋于紧缩。但是背面两步——高质料数据的微和谐基于强化学习的东谈主类偏好对皆,我信赖异日会有更多的参加。
NBD:DeepSeek遴荐开源款式,与许多国际大模子巨头闭源的作念法不同。您怎么看开源模子在推动AI行业发展中的作用?
郑骁庆:DeepSeek咫尺受到了平方地热心和认同。从开源模子与闭源模子的角度来看,咱们不雅察到,开源模子在累积了以往盘问抑止的基础上,在主义明确的情况之下,借助于多样磨练技巧以及模子结构上的优化,越过是接纳先前盘问者在大模子领域已考据有用的旨趣和设施,开源模子已大概大要追上闭源模子。
开源模子最大的克己就在于,一朝模子开源,全球的顶尖东谈主才都能基于这些代码进行进一步的迭代与优化,这无疑加快了这个模子的更新与发展进度。比拟之下,闭源模子信赖是莫得这么的智商的,只可靠领有这个闭源模子所属机构的里面东谈主才去推动模子的迭代,迭代速率相对受限。
另外,开源模子透明洞开,也缓解了公众关于大模子使用安全的一些费心。如果模子闭源,寰球在使用过程当中可能或多或少会有一些费心。况且开源模子关于东谈主工智能的普及以及全球范围内的平正哄骗起到了相当好的促进作用,越过是技艺平权方面。也就是说,当一项科学技艺发展起来以后,全宇宙的东谈主,岂论来自哪个国度、身处何地,都哄骗享有对等地享受这种技艺所带来的上风过火产生的经济效益。
NBD:DeepSeek团队成员多为国内顶尖高校的应届毕业生、在校博士生。您认为中国AI是否存在独到的竞争上风?
郑骁庆:我认为咱们的AI上头的竞争上风,其实是咱们的东谈主才数目上的上风。这几年,从我个东谈主来看,咱们的高级训导,包括硕士、博士的培养,有了长足朝上。咫尺从中国的头部高校来看,对博士生、硕士生的培养依然比较接近于好意思国。
在这么的情况之下,咱们的基础高级训导质料的栽培,使得咱们储备了多半的东谈主才。在这么的过程当中,咱们大概对现存的技艺进行赶紧的消化。
现实上,好意思国许多大模子盘问团队,不乏有华东谈主的身影。寰球开打趣说,咫尺的东谈主工智能竞争是在中国的中国东谈主和在好意思国的中国东谈主竞争。要说颓势,其实我认为如故很缺憾的,那就是咱们很少能有颠覆性的创新。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
包袱剪辑:丁文武